
 08/04/2025
08/04/2025
Phân vùng ảnh là một kỹ thuật quan trọng, giữ vai trò then chốt trong lĩnh vực thị giác máy tính (Computer Vision), giúp máy tính không chỉ "nhìn" mà còn hiểu hình ảnh một cách chính xác. Vậy, phân vùng ảnh là gì? Công nghệ này hoạt động ra sao và đang được ứng dụng rộng rãi trong những lĩnh vực nào? Hãy cùng VNPT AI khám phá chi tiết hơn trong bài viết dưới đây!
Phân vùng ảnh là gì?
Phân vùng ảnh (Image Segmentation) là một kỹ thuật quan trọng trong lĩnh vực thị giác máy tính (Computer Vision), giúp chia một hình ảnh kỹ thuật số thành nhiều vùng nhỏ hơn nhằm đơn giản hóa hoặc thay đổi cách biểu diễn của hình ảnh để dễ phân tích hơn. Quá trình này giúp xác định ranh giới giữa các đối tượng trong ảnh và gán nhãn cho từng vùng ảnh cụ thể, từ đó cho phép các hệ thống máy tính nhận diện và phân loại chính xác từng thành phần trong hình ảnh.
So với các phương pháp nhận diện thông thường như phát hiện vật thể (Object Detection), phân vùng ảnh hoạt động với độ chính xác cao hơn khi yêu cầu dự đoán nhãn đến từng pixel. Điều này làm cho Image Segmentation trở thành một phương pháp vượt trội trong việc xử lý các bài toán phức tạp như nhận diện y khoa, xe tự hành hay phân tích ảnh vệ tinh.
Về nguyên tắc hoạt động, quá trình phân đoạn ảnh có thể thực hiện dựa trên nhiều tiêu chí khác nhau như màu sắc, cường độ sáng, kết cấu bề mặt, hoặc dựa vào các mô hình học sâu hiện đại - image segmentation deep learning.
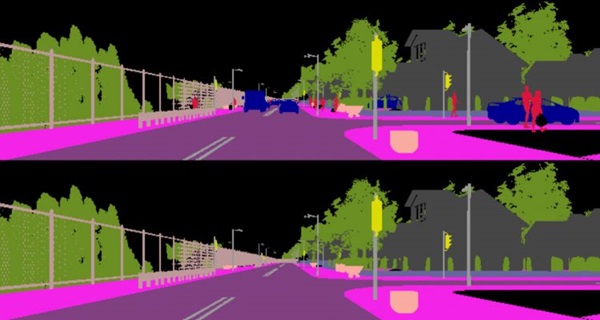
Giải thích các lớp ngữ nghĩa trong phân vùng ảnh
Một trong những khía cạnh quan trọng của phân đoạn ảnh là xác định các lớp ngữ nghĩa trong hình ảnh. Các lớp này thường được chia thành hai nhóm chính: “things” (đối tượng cụ thể) và “stuff” (vật liệu, môi trường nền).
Nhóm “Things”: Các đối tượng có hình dạng cụ thể
“Things” là những thực thể có hình dạng rõ ràng và có thể đếm được, chẳng hạn như xe hơi, cây cối, con người, động vật. Các đối tượng này thường có ranh giới cụ thể và có kích thước tương đối đồng nhất giữa các cá thể. Ví dụ, một chiếc xe có các bộ phận như bánh xe, cửa kính,... một bánh xe riêng lẻ không thể được xem là một chiếc xe hoàn chỉnh.
Trong phân đoạn ảnh, nhóm “things” thường được xử lý bằng phân đoạn theo từng đối tượng (Instance Segmentation), giúp xác định và phân biệt từng cá thể riêng lẻ trong hình ảnh. Điều này đặc biệt hữu ích trong các ứng dụng như xe tự hành, giám sát an ninh hoặc phân tích y tế.
Nhóm “Stuff”: Các vật liệu có tính liên tục
Ngược lại với “things”, “stuff” là các lớp ngữ nghĩa không có hình dạng cố định, thường bao phủ một vùng rộng lớn trong ảnh như bầu trời, mặt nước, bãi cỏ hoặc mặt đường. Chúng không có các cá thể riêng biệt có thể đếm được mà thường được coi là một vùng liên tục trong ảnh.
Ví dụ, một cánh đồng cỏ có thể chứa nhiều nhánh cỏ nhỏ, nhưng thay vì xem mỗi nhánh là một đối tượng riêng, hệ thống sẽ phân loại toàn bộ vùng này là "grass" (cỏ). Phân đoạn ảnh trong nhóm “stuff” thường được xử lý bằng phân đoạn ngữ nghĩa (Semantic Segmentation) giúp xác định vùng nào thuộc về lớp nào mà không cần phân biệt từng cá thể cụ thể.

Mối quan hệ giữa Things và Stuff trong phân đoạn ảnh
Trong thực tế, mối quan hệ giữa các lớp ngữ nghĩa không cố định mà có thể thay đổi tùy theo ngữ cảnh. Trong một số trường hợp, cùng một đối tượng có thể được phân loại là 'things' hoặc 'stuff' tùy vào cách tiếp cận phân đoạn ảnh.
Ví dụ, trong một số trường hợp, cùng một đối tượng có thể được xem là “things” hoặc “stuff” tùy thuộc vào ngữ cảnh và cách tiếp cận phân đoạn. Chẳng hạn, nếu một nhóm người đứng riêng lẻ, hệ thống có thể xác định từng cá thể là 'things'. Nhưng nếu họ tạo thành một đám đông lớn mà không thể phân biệt từng người riêng lẻ, hệ thống có thể coi toàn bộ đám đông đó là một lớp “stuff”.
Ngoài ra, “things” và “stuff” cũng có thể hỗ trợ lẫn nhau trong quá trình nhận diện hình ảnh. Ví dụ, một vật thể kim loại trên đường cao tốc nhiều khả năng là một chiếc xe hơi, vì ngữ cảnh xung quanh là mặt đường. Tương tự, nền xanh phía sau con thuyền có thể được xác định là nước, trong khi nếu xuất hiện sau máy bay, nhiều khả năng đó là bầu trời.
Chính sự kết hợp giữa “things” và “stuff” giúp các mô hình học sâu như image segmentation deep learning có thể hiểu và phân đoạn ảnh một cách chính xác hơn. Điều này đóng vai trò quan trọng đối với nhiều lĩnh vực đời sống, từ thị giác máy tính, bản đồ học đến phân tích dữ liệu y tế và sản xuất xe tự hành,...
Phân loại tác vụ phân vùng hình ảnh phổ biến
Phân vùng ảnh được chia thành 3 loại tác vụ chính, bao gồm: phân đoạn ngữ nghĩa (Semantic Segmentation), phân đoạn theo đối tượng (Instance Segmentation) và phân đoạn toàn cảnh (Panoptic Segmentation).
Semantic segmentation
Phân đoạn ngữ nghĩa là hình thức đơn giản nhất của phân đoạn ảnh, trong đó mỗi pixel trong hình ảnh được gán nhãn theo một lớp ngữ nghĩa cụ thể mà không quan tâm đến từng cá thể riêng lẻ. Điều này có nghĩa là mọi đối tượng thuộc cùng một lớp ngữ nghĩa sẽ được nhóm lại, mà không phân biệt các cá thể riêng biệt.
Ví dụ, nếu một mô hình semantic segmentation được huấn luyện để phân loại các yếu tố trên đường phố, nó có thể xác định và đánh dấu toàn bộ vùng chứa xe cộ, cột đèn, đường phố hoặc vỉa hè. Tuy nhiên, nó không phân biệt giữa các xe riêng lẻ mà chỉ coi tất cả xe trong ảnh như một vùng thống nhất thuộc lớp “xe”. Do đó, trong trường hợp có nhiều vật thể cùng loại xuất hiện gần nhau, mô hình này có thể mất đi chi tiết quan trọng.
Semantic segmentation thường được ứng dụng trong các bài toán như bản đồ địa lý, phân tích y tế, hoặc tự động phát hiện vùng quan tâm trong ảnh.
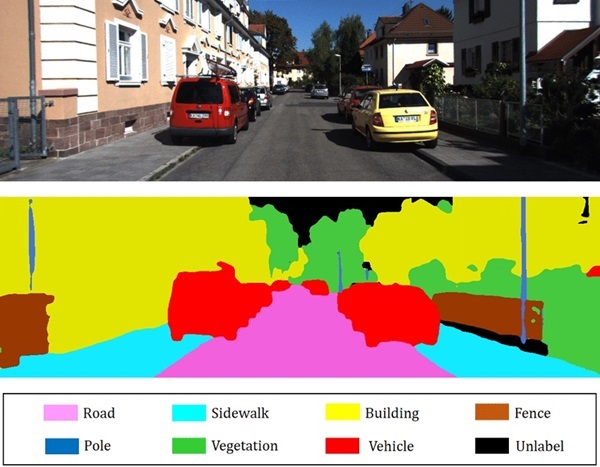
Instance segmentation
Khác với semantic segmentation, phân đoạn theo đối tượng (Instance segmentation) không chỉ xác định lớp ngữ nghĩa của từng pixel mà còn xác định từng đối tượng riêng biệt trong hình ảnh. Nghĩa là dù hai vật thể thuộc cùng một lớp, chúng vẫn được mô hình nhận diện là hai đối tượng riêng biệt.
Ví dụ, nếu một bức ảnh chứa nhiều người, semantic segmentation sẽ chỉ đánh dấu toàn bộ vùng đó là "người", trong khi instance segmentation sẽ phân biệt từng người trong đám đông và xác định hình dạng chính xác của mỗi cá thể. Điều này đặc biệt quan trọng trong các ứng dụng như giám sát an ninh, đếm số lượng người trong sự kiện, hoặc phân tích hành vi khách hàng trong bán lẻ.

Panoptic segmentation
Panoptic segmentation là bước tiến mới nhất trong phân đoạn ảnh, kết hợp những ưu điểm của cả semantic segmentation và instance segmentation. Trong tác vụ này, mỗi pixel không chỉ được gán nhãn theo lớp ngữ nghĩa mà còn có ID riêng nếu thuộc về một đối tượng cụ thể.
Điều này đồng nghĩa với việc panoptic segmentation có thể xác định cả các đối tượng có ranh giới rõ ràng (things) và các vùng vật liệu liên tục (stuff) trong cùng một hình ảnh. Ví dụ, trong một bức ảnh về đường phố, tác vụ này có có thể:
- Xác định mỗi chiếc xe là một đối tượng riêng biệt (giống instance segmentation).
- Phân loại bầu trời, đường phố, cây cối như các vùng vật liệu nền (giống semantic segmentation).
Tuy nhiên, vì phải xử lý đồng thời cả hai tác vụ trên, panoptic segmentation đòi hỏi mô hình phức tạp hơn, thường sử dụng các mạng sâu như EfficientPS, UPSNet hay PanopticFPN để tối ưu tốc độ và độ chính xác. Các ứng dụng tiêu biểu của kỹ thuật này bao gồm xe tự hành, robot thông minh, phân tích cảnh quan đô thị hoặc mô phỏng môi trường thực tế ảo,...

Các kỹ thuật trong Image Segmentation
Hiện nay, có nhiều kỹ thuật khác nhau được sử dụng trong Image Segmentation, mỗi kỹ thuật đều có những ưu và nhược điểm riêng, được khai thác để phù hợp với những bài toán cụ thể.
Phân vùng dựa trên ngưỡng (Threshold-Based Segmentation)
Phân vùng theo ngưỡng - Một trong những kỹ thuật trong phân vùng ảnh đơn giản nhất, chia hình ảnh thành hai hoặc nhiều vùng dựa trên giá trị cường độ pixel. Kỹ thuật này hoạt động bằng cách xác định một ngưỡng (threshold) để phân loại các pixel: những pixel có giá trị cao hơn ngưỡng sẽ được gán vào một vùng, trong khi những pixel thấp hơn sẽ thuộc về vùng còn lại. Phương pháp này phù hợp với các hình ảnh có độ tương phản rõ ràng giữa nền và đối tượng, nhưng kém hiệu quả khi xử lý những hình ảnh phức tạp hoặc bị nhiễu.
Phân vùng dựa trên cạnh (Edge-Based Segmentation)
Phương pháp này dựa vào việc xác định các biên giới giữa các đối tượng bằng cách tìm kiếm sự gián đoạn về độ sáng hoặc kết cấu trong hình ảnh. Các bước xử lý gồm phát hiện cạnh bằng các bộ lọc như Sobel, Canny, Prewitt, sau đó liên kết các cạnh này để xác định đường biên của đối tượng. Mặc dù hiệu quả với các hình ảnh có biên giới rõ ràng, nhưng kỹ thuật này có thể gây khó khăn khi xử lý các hình ảnh bị nhiễu hoặc các đối tượng trong ảnh bị chồng lên nhau.
Phân vùng dựa trên khu vực (Region-Based Segmentation)
Không giống như phương pháp phát hiện cạnh, kỹ thuật này dựa vào sự đồng nhất của các vùng để nhóm các pixel có cùng đặc điểm thành từng cụm. Hai phương pháp phổ biến trong nhóm này là Region Growing và Region Splitting & Merging. Trong Region Growing, quá trình bắt đầu từ một số pixel hạt giống, sau đó mở rộng vùng dựa trên tiêu chí tương đồng. Ngược lại, Region Splitting & Merging bắt đầu bằng việc chia ảnh thành nhiều vùng nhỏ và sau đó hợp nhất những vùng có đặc tính tương tự.
Phân vùng dựa trên kỹ thuật phân cụm (Clustering-Based Segmentation)
Kỹ thuật phân cụm (Clustering) sử dụng các thuật toán học máy không giám sát để nhóm các pixel có đặc điểm giống nhau vào cùng một cụm. Một trong những thuật toán phổ biến nhất là K-Means Clustering, trong đó dữ liệu hình ảnh được chia thành K cụm dựa trên sự tương đồng về màu sắc, cường độ hoặc kết cấu. Quá trình lặp lại đến khi các cụm ổn định. Đây là một phương pháp linh hoạt nhưng có thể bị ảnh hưởng bởi việc lựa chọn số lượng cụm K.
Phân vùng dựa trên mô hình địa hình - Watershed Segmentation
Phương pháp Watershed coi hình ảnh dưới dạng bản đồ địa hình, trong đó độ sáng của pixel đại diện cho độ cao. Bằng cách giả lập quá trình nước tràn từ các vùng thấp, thuật toán có thể xác định các ranh giới giữa các đối tượng. Tuy nhiên, phương pháp này dễ bị phân đoạn quá mức, đòi hỏi phải có các kỹ thuật xử lý bổ sung để tối ưu kết quả.
Phân vùng dựa trên mạng nơron nhân tạo (Artificial Neural Network-Based Segmentation)
Với sự phát triển của trí tuệ nhân tạo, các phương pháp phân vùng ảnh dựa trên mạng nơron nhân tạo ngày càng được ưa chuộng. Neural Network là một trong những kiến trúc phổ biến nhất trong phân vùng ảnh, có khả năng học đặc trưng phức tạp của hình ảnh. Đặc biệt là mô hình Mask R-CNN cho phép xác định và phân vùng từng đối tượng trong ảnh với độ chính xác cao. Phương pháp này phù hợp với các bài toán phức tạp như phân tích y tế, xe tự hành hay thực tế ảo, nhưng đòi hỏi lượng tài nguyên tính toán lớn.
Một số mô hình Deep Learning phổ biến dùng trong phân vùng ảnh
Với sự phát triển mạnh mẽ của Deep Learning, các mô hình mạng nơ-ron ngày càng cho thấy hiệu quả vượt trội trong bài toán phân đoạn ảnh. Không chỉ phân tích hình ảnh một cách chi tiết, các mô hình này còn giúp nhận diện chính xác các đối tượng trong ảnh với tốc độ nhanh chóng.
Fully Convolutional Networks (FCN)
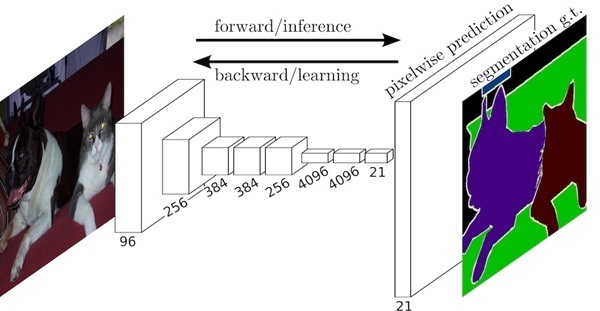
Fully Convolutional Networks (FCN) được xem là một trong những mô hình tiên phong trong phân đoạn ảnh. Không giống như các mạng nơ-ron tích chập (CNN) truyền thống vốn chỉ có thể phân loại hình ảnh, FCN loại bỏ các lớp fully connected (kết nối đầy đủ) và thay thế bằng các lớp tích chập hoàn toàn (fully convolutional). Cấu trúc của FCN bao gồm hai thành phần chính: mạng encoder giúp trích xuất đặc trưng từ ảnh đầu vào và mạng decoder có nhiệm vụ tái tạo thông tin để dự đoán nhãn cho từng pixel. Nhờ đó, FCN có thể tạo ra bản đồ phân đoạn chính xác và được ứng dụng rộng rãi trong bài toán phân vùng ảnh y khoa, ảnh vệ tinh và nhận diện đối tượng.
U-Net
Là một cải tiến từ FCN, U-Net được thiết kế đặc biệt để giải quyết bài toán phân đoạn ảnh với dữ liệu hạn chế, điển hình là trong lĩnh vực y tế. Điểm khác biệt nổi bật của U-Net nằm ở cấu trúc đối xứng hình chữ U, trong đó các skip connections (kết nối bỏ qua) giúp truyền trực tiếp thông tin từ các lớp xuống mẫu đến các lớp lên mẫu, hạn chế tối đa sự mất mát thông tin. Nhờ đó, mô hình có thể giữ lại nhiều chi tiết quan trọng và cải thiện độ chính xác trong phân đoạn ảnh. Với hiệu suất cao và khả năng tổng quát hóa tốt, U-Net trở thành một trong những mô hình phổ biến nhất trong lĩnh vực xử lý ảnh y sinh và phân đoạn hình ảnh nói chung.
DeepLab
DeepLab là một dòng mô hình gần giống như Unet, do Google phát triển, được tối ưu hóa cho bài toán phân đoạn ảnh với độ chính xác cao. Một trong những điểm đặc trưng nổi bật của DeepLab là sử dụng kỹ thuật Atrous Convolution (tích chập giãn) giúp tăng độ phân giải của bản đồ đặc trưng mà không làm tăng số lượng tham số hay chi phí tính toán. Bên cạnh đó, DeepLab còn tích hợp Conditional Random Fields (CRFs) để cải thiện tính mượt mà của các biên đối tượng, giúp phân đoạn chính xác hơn trong những bức ảnh có độ phức tạp cao.
Mask R-CNN
Trong bài toán phân đoạn từng đối tượng riêng lẻ (Instance Segmentation), Mask R-CNN là một trong những mô hình hàng đầu. Được xây dựng dựa trên Faster R-CNN, Mask R-CNN không chỉ nhận diện và khoanh vùng đối tượng mà còn tạo ra mặt nạ phân đoạn chính xác cho từng đối tượng trong ảnh. Cấu trúc của Mask R-CNN bao gồm hai phần chính: Region Proposal Network (RPN) để xác định vùng chứa đối tượng và mask branch để tạo ra mặt nạ phân đoạn cho từng vùng.
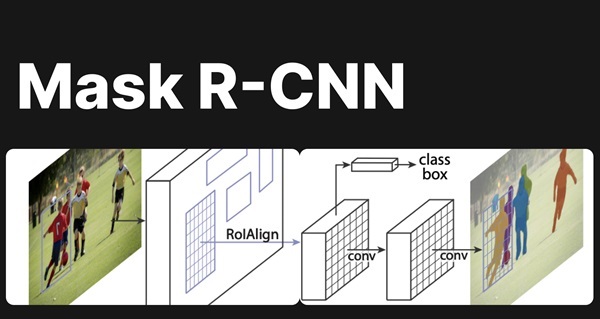
Mask R-CNN nhận diện và khoanh vùng đối tượng đồng thời tạo ra mặt nạ phân đoạn chính xác cho từng đối tượng trong ảnh
Vision Transformer (ViT)
Trong khi hầu hết các mô hình phân đoạn ảnh truyền thống dựa trên mạng CNN, Vision Transformer (ViT) mang đến một cách tiếp cận mới bằng việc áp dụng cơ chế Self-Attention từ mô hình Transformer. Thay vì sử dụng tích chập để trích xuất đặc trưng, ViT chia ảnh thành các patch nhỏ và xử lý chúng như một chuỗi dữ liệu, tương tự cách Transformer hoạt động trong xử lý ngôn ngữ tự nhiên. Cách tiếp cận này giúp ViT đạt hiệu suất cao hơn so với các mô hình CNN truyền thống trong một số tác vụ, đặc biệt là khi được huấn luyện trên lượng dữ liệu lớn.
Ứng dụng của Imagine Segmentation trong thực tiễn
Ngày nay, Image Segmentation được nhắc tới trong khá nhiều lĩnh vực, ngành nghề đa dạng như Y Tế, Nông nghiệp, An ninh,…
Y học - Nâng cao khả năng chẩn đoán và điều trị
Nói tới những ứng dụng của phân vùng ảnh trong lĩnh vực y tế phải kể đến vai trò của công nghệ này trong việc hỗ trợ bác sĩ chuẩn đoán và đưa ra phác đồ điều trị. Các thuật toán Image Segmentation giúp xác định chính xác vị trí và hình dạng của các cơ quan nội tạng, khối u, hoặc tổn thương từ các ảnh X-quang, MRI, CT-Scan. Nhờ đó, bác sĩ có thể đưa ra phác đồ điều trị phù hợp, đồng thời hỗ trợ phẫu thuật chính xác hơn. Ví dụ: trong điều trị ung thư, mô hình phân đoạn ảnh giúp xác định ranh giới giữa mô lành và mô bệnh, nâng cao hiệu quả xạ trị và phẫu thuật.
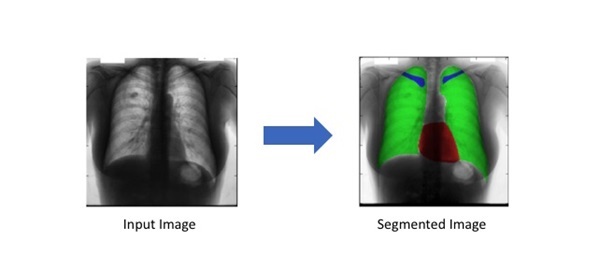
Xe tự hành - Nhận diện môi trường giao thông
Để vận hành an toàn, xe tự hành cần phải nhận thức và phản ứng nhanh với các yếu tố xung quanh. Image Segmentation được sử dụng để phát hiện và phân loại các đối tượng như người đi bộ, phương tiện, đèn tín hiệu, biển báo giao thông và vạch kẻ đường. Nhờ đó, xe có thể đưa ra quyết định chính xác khi di chuyển trên đường. Hơn nữa, công nghệ này còn giúp tối ưu hóa hệ thống cảnh báo va chạm, hỗ trợ đỗ xe tự động và cải thiện khả năng điều hướng trong các môi trường phức tạp.
Xử lý ảnh vệ tinh - Quan sát và dự báo thiên tai
Mỗi ngày, vệ tinh cung cấp một lượng dữ liệu khổng lồ về bề mặt Trái Đất và Image Segmentation có vai trò phân tích những dữ liệu này một cách hiệu quả. Các mô hình phân đoạn ảnh có thể xác định rõ ràng ranh giới giữa sông, núi, rừng, khu đô thị và vùng biển. Ứng dụng này rất quan trọng trong quy hoạch đô thị, giám sát rừng và dự đoán biến đổi khí hậu. Ngoài ra, trong cảnh báo thiên tai, thuật toán phân đoạn ảnh giúp phát hiện cháy rừng, xác định khu vực bị ngập lụt hoặc theo dõi sự thay đổi của sông băng, giúp chính phủ và các tổ chức quốc tế kịp thời đưa ra phương án ứng phó.
Nông nghiệp thông minh - Giám sát cây trồng và tối ưu hóa sản xuất
Trong nông nghiệp, Image Segmentation ứng dụng để theo dõi sức khỏe cây trồng, phát hiện dịch bệnh và tối ưu hóa việc sử dụng phân bón, nước tưới. Các hệ thống phun thuốc trừ sâu thông minh có thể phân biệt được diện tích cây trồng và cỏ dại, từ đó chỉ phun thuốc vào những khu vực cần thiết, giúp giảm thiểu ô nhiễm môi trường và tiết kiệm chi phí. Ngoài ra, công nghệ này còn hỗ trợ trong việc dự đoán năng suất mùa vụ bằng cách phân tích màu sắc, mật độ lá và mức độ phát triển của cây trồng qua hình ảnh vệ tinh hoặc drone.

An ninh và giám sát - Nhận diện đối tượng trong thời gian thực
Phân đoạn ảnh đóng vai trò quan trọng trong lĩnh vực giám sát an ninh bằng camera. Nhờ vào khả năng phân biệt rõ ràng từng đối tượng trong hình ảnh hoặc video, công nghệ này giúp phát hiện hành vi đáng ngờ, nhận diện khuôn mặt và kiểm soát đám đông hiệu quả. Trong lĩnh vực quốc phòng, Image Segmentation cũng được ứng dụng để phân tích hình ảnh từ máy bay không người lái (UAV), giúp phát hiện các hoạt động bất thường hoặc xác định vị trí mục tiêu trong điều kiện phức tạp.
Công nghiệp sản xuất - Kiểm tra chất lượng sản phẩm
Trong các dây chuyền sản xuất, kiểm tra chất lượng sản phẩm là một khâu quan trọng để đảm bảo tiêu chuẩn đầu ra.Trong đó, các hệ thống kiểm tra chất lượng tự động sử dụng công nghệ Image Segmentation để phát hiện các lỗi nhỏ trên bề mặt sản phẩm như vết nứt, trầy xước hoặc sai lệch kích thước. Nhờ cải tiến này, các đơn vị sản xuất có thể giảm thiểu tối đa các sai sót, tăng tốc độ kiểm định sản phẩm và đảm bảo tính đồng nhất của sản phẩm trước khi xuất xưởng.
Xử lý nội dung số - Lọc nội dung không phù hợp trên mạng xã hội
Trong thời đại số hóa, các nền tảng mạng xã hội phải đối mặt với lượng lớn nội dung được tải lên mỗi ngày. Kết hợp với AI, Image Segmentation giúp phát hiện và loại bỏ những hình ảnh, video có nội dung nhạy cảm hoặc không phù hợp một cách tự động. Điều này góp phần tạo ra một môi trường mạng an toàn và lành mạnh hơn, đồng thời giảm tải công việc cho các đội ngũ kiểm duyệt nội dung.
Những thách thức trong phân vùng ảnh
Dù Image Segmentation đã trở nên khá phổ biến và được sử dụng trong nhiều lĩnh vực, nhưng quá trình triển khai công nghệ này vẫn gặp phải một số thách thức như:
Tăng chất lượng và đa dạng hóa dữ liệu
Hiệu quả của các mô hình phân đoạn ảnh phụ thuộc đáng kể vào chất lượng và sự đa dạng của dữ liệu huấn luyện. Nếu dữ liệu huấn luyện không đủ đa dạng, mô hình có thể gặp khó khăn trong việc tổng quát hóa, dẫn đến kết quả phân đoạn không chính xác trên các trường hợp thực tế. Điều này đặc biệt quan trọng trong các ứng dụng như y tế hay xe tự hành, nơi mà mỗi sai sót nhỏ đều có thể gây ra hậu quả nghiêm trọng. Để khắc phục, việc thu thập dữ liệu phong phú từ nhiều điều kiện ánh sáng, góc nhìn và môi trường khác nhau, kết hợp với các kỹ thuật tăng cường dữ liệu (Data Augmentation) như xoay, lật, cắt xén hay làm nhiễu màu được xem là vô cùng cần thiết để cải thiện độ bền vững của mô hình.

Lựa chọn và tối ưu hóa thuật toán phù hợp
Với sự phát triển của nhiều mô hình phân đoạn ảnh như U-Net, Mask R-CNN, hay FCN,... việc lựa chọn một thuật toán phù hợp cho từng bài toán cụ thể không hề đơn giản. Mỗi mô hình có ưu và nhược điểm riêng, nên tiến hành thử nghiệm và đánh giá kỹ lưỡng để đảm bảo hiệu suất tối ưu nhất. Bên cạnh đó, các tham số của mô hình cũng cần được tinh chỉnh cẩn thận để tránh tình trạng quá khớp (overfitting) hoặc dưới khớp (underfitting). Để giải quyết vấn đề này, có thể áp dụng các phương pháp như tìm kiếm lưới (Grid Search), tìm kiếm ngẫu nhiên (Random Search) hay tối ưu hóa Bayesian để có thể giúp xác định các tham số tốt nhất, đồng thời kết hợp nhiều mô hình để tận dụng ưu điểm của từng phương pháp.
Yêu cầu cao về tài nguyên tính toán
Các mô hình phân đoạn ảnh hiện đại, đặc biệt là các mô hình được phát triển dựa trên học sâu (deep learning) thường yêu cầu lượng lớn tài nguyên tính toán. Điều này đặt ra thách thức lớn khi triển khai trên các thiết bị có cấu hình hạn chế hoặc khi xử lý các tập dữ liệu lớn trong thời gian thực. Để tối ưu hóa hiệu suất, có thể sử dụng các phương pháp như tăng tốc bằng GPU, xử lý song song, nén mô hình (pruning, quantization, knowledge distillation), hoặc tận dụng các dịch vụ điện toán đám mây. Những giải pháp này không chỉ giúp tăng tốc độ xử lý mà còn giảm thiểu chi phí vận hành.

Tích hợp với các hệ thống hiện có
Trong nhiều ứng dụng thực tế, mô hình phân đoạn ảnh cần được tích hợp vào các hệ thống hiện có, chẳng hạn như phần mềm y tế, xe tự hành hoặc hệ thống giám sát an ninh. Tuy nhiên, sự khác biệt về định dạng dữ liệu, giao thức truyền thông và môi trường triển khai có thể gây ra nhiều khó khăn. Để giải quyết vấn đề này, cần xây dựng các hệ thống phân đoạn dưới dạng các thành phần mô-đun với giao diện lập trình ứng dụng (API) rõ ràng, giúp quá trình tích hợp trở nên linh hoạt và dễ dàng hơn. Ngoài ra, tài liệu hướng dẫn chi tiết cùng với các mẫu mã nguồn có thể hỗ trợ các nhà phát triển trong việc triển khai và khắc phục lỗi.
Đảm bảo độ chính xác cao trong điều kiện phức tạp
Trong thực tế, phân đoạn ảnh thường gặp phải nhiều yếu tố ảnh hưởng đến độ chính xác như: hình dạng vật thể phức tạp, điều kiện ánh sáng không ổn định, hiện tượng che khuất hoặc nhiễu hình ảnh,... Điều này đặc biệt quan trọng trong các ứng dụng y tế và an ninh, nơi mà mỗi quyết định dựa trên kết quả phân đoạn có thể tác động trực tiếp đến tính mạng con người.
Để đánh giá chất lượng của mô hình, có thể sử dụng các chỉ số như IoU (Intersection over Union), Dice Coefficient, đo độ chính xác pixel,.... Bên cạnh đó, việc tinh chỉnh mô hình qua nhiều vòng huấn luyện và xác thực cũng sẽ giúp cải thiện độ chính xác, giảm thiểu sai số và đảm bảo hiệu suất ổn định trong các điều kiện thực tế khác nhau.

Một số công cụ phổ biến hỗ trợ phân vùng ảnh
Để thực hiện hiệu quả nhiệm vụ phân đoạn vùng ảnh, nhiều công cụ và thư viện đã được phát triển nhằm hỗ trợ xử lý, huấn luyện và triển khai các mô hình phân đoạn ảnh. Dưới đây là một số công cụ phổ biến đáng chú ý:
- FastAI: FastAI là một thư viện học sâu mạnh mẽ giúp đơn giản hóa việc xây dựng và huấn luyện mô hình phân đoạn ảnh. Thư viện này sẽ cung cấp các công cụ cho quá trình tiền xử lý dữ liệu, xây dựng mô hình và huấn luyện, giúp người dùng dễ dàng triển khai các giải pháp phân đoạn ảnh.
- DeepMask: DeepMask được phát triển bởi Facebook Research, là một nền tảng triển khai dựa trên Torch, cho phép phát hiện và tạo mặt nạ phân đoạn cho các đối tượng trong hình ảnh. Công cụ này giúp cải thiện độ chính xác trong các bài toán phân đoạn ảnh nhờ vào kiến trúc mô hình tiên tiến.
- MultiPath: MultiPath là một kiến trúc phát hiện đối tượng được xây dựng dựa trên Torch, phục vụ chủ yếu cho việc phát hiện đối tượng với độ chính xác cao.
- OpenCV: OpenCV là một thư viện mã nguồn mở nổi tiếng với hơn 2.500 thuật toán thị giác máy tính, hỗ trợ mạnh mẽ cho các tác vụ như nhận diện đối tượng, theo dõi chuyển động và đặc biệt là phân đoạn ảnh. Với sự tối ưu hóa cao, OpenCV được sử dụng rộng rãi trong cả nghiên cứu và ứng dụng thực tiễn.
- MIScnn: MIScnn là một thư viện mã nguồn mở chuyên biệt cho phân đoạn ảnh y tế. Nó cho phép thiết lập các pipeline với các mô hình học sâu hiện đại, hỗ trợ quá trình huấn luyện và triển khai mô hình với chỉ một vài dòng mã đơn giản.
Tạm kết
Trên đây là những nội dung xoay quanh khái nhiệm “Phân vùng ảnh là gì” mà VNPT AI muốn truyền tải tới bạn đọc. Nhìn chung, phân vùng ảnh là một kỹ thuật nền tảng và không thể thiếu trong lĩnh vực thị giác máy tính, đóng vai trò then chốt trong việc cho phép máy móc "hiểu" và phân tích cấu trúc của thế giới hình ảnh. Với những ứng dụng thực tiễn từ y tế, nông nghiệp đến phân tích dữ liệu vệ tinh,... phân vùng ảnh sẽ tiếp tục được phát triển nhiều hơn nữa trong thời gian tới.




.png)